
AI-Driven Near-Lossless Audio Compression Modeling via Autoencoders
Article Sidebar
Main Article Content
Abstract
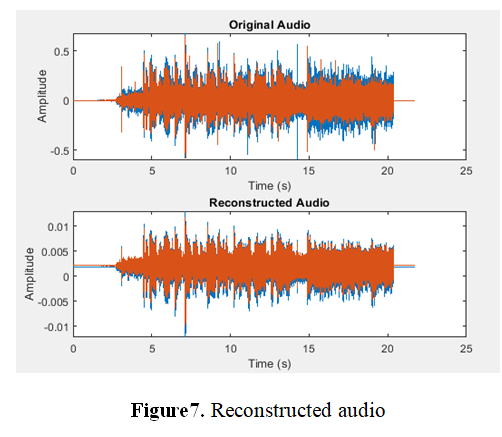
Near-Lossless audio compression is an important aspect of efficient data storage and transmission in various audio-related applications. Traditional compression algorithms often rely on mathematical techniques and signal processing methods to reduce file size while maintaining the original audio quality. However, deep learning-based methods have shown promising results in achieving better compression performance. This study explores the application of deep learning techniques for Near-Lossless audio compression. Deep neural networks (DNNs) and recurrent neural networks (RNNs) are used to learn compressed representations of audio data that can be efficiently reconstructed without any information loss. Models have been trained on a large dataset of unannotated audio samples to capture complex patterns and dependencies in the data. Experimental results demonstrated a compression ratio of 0.0333 (30:1) with a mean squared error (MSE) of 4.3957e-06, outperforming traditional compression algorithms such as FLAC (compression ratio: 0.1879) in both compression efficiency and reconstruction quality. In addition, the trained models showed robust generalization to unseen audio samples. Overall, this study contributes to the advancement of Near-Lossless audio compression techniques using deep learning methodologies.
Article Details
Section

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Licensed under a CC-BY license: https://creativecommons.org/licenses/by-nc-sa/4.0/
How to Cite




References
C. H. Chi, C. K. Kan, K. S. Cheng, and L. Wong, “Extending Huffman coding for multilingual text compression,” in Data Compression Conference Proceedings, 1995, p. 437. doi: 10.1109/dcc.1995.515547.
Fowler, J. E., & Yagel, R. (1995). Optimal linear prediction for the lossless compression of volume data. Data Compression Conference Proceedings, 458. doi:10.1109/dcc.1995.515568
Franceschini, R., & Mukherjee, A. (1996). Data compression using encrypted text. Proceedings of the Forum on Research and Technology Advances in Digital Libraries (ADL), 130–138. doi:10.1109/dcc.1996.488369
Bhattacharjee, A. K. B. A. K. (2013). Comparison study of lossless data compression algorithms for text data. IOSR Journal of Computer Engineering, *11*(6), 15–19. doi:10.9790/0661-1161519
Jain, A., & Patel, R. (2009). An efficient compression algorithm (ECA) for text data. 2009 International Conference on Signal Processing Systems (ICSPS), 762–765. doi:10.1109/ICSPS.2009.96
Shukla, S., Gupta, R., Rajput, D. S., Goswami, Y., & Sharma, V. (2022). A comparative analysis of lossless compression algorithms on uniformly quantized audio signals. International Journal of Image, Graphics and Signal Processing, *14*(6), 59–69. doi:10.5815/ijigsp.2022.06.05
Dubois, Y., Bloem-Reddy, B., Ullrich, K., & Maddison, C. J. (2021). Lossy compression for lossless prediction. Advances in Neural Information Processing Systems, *34*, 14014–14028.
Barman, R., Badade, S., Deshpande, S., Agarwal, S., & Kulkarni, N. (2022). Lossless data compression method using deep learning. In Machine Intelligence and Smart Systems (pp. 145–151). Springer. doi:10.1007/978-981-16-9650-3_11
Shukla, S., Ahirwar, M., Gupta, R., Jain, S., & Rajput, D. S. (2019). Audio compression algorithm using discrete cosine transform (DCT) and Lempel-Ziv-Welch (LZW) encoding method. Proceedings of the International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), 476–480. doi:10.1109/COMITCon.2019.8862228
Hennequin, R., Royo-Letelier, J., & Moussallam, M. (2017). Codec independent lossy audio compression detection. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 726–730. doi:10.1109/ICASSP.2017.7952251
Schuller, G. D. T., Yu, B., Huang, D., & Edler, B. (2002). Perceptual audio coding using adaptive pre- and post-filters and lossless compression. IEEE Transactions on Speech and Audio Processing, *10*(6), 379–390. doi:10.1109/TSA.2002.803444
Ramesh, V., & Wang, M. (2021). ClefNet: Recurrent autoencoders with dynamic time warping for near-lossless music compression and minimal-latency transmission. Preprints. doi:10.20944/preprints202103.0360.v1
Friedland, G., Jia, R., Wang, J., Li, B., & Mundhenk, N. (2020). On the impact of perceptual compression on deep learning. 3rd International Conference on Multimedia Information Processing and Retrieval (MIPR), 219–224. doi:10.1109/MIPR49039.2020.00052
Mineo, T., & Shouno, H. (2022). Improving sign-algorithm convergence rate using natural gradient for lossless audio compression. EURASIP Journal on Audio, Speech, and Music Processing, *2022*(1), 12. doi:10.1186/s13636-022-00243-w
Liu, Y. (2021). Recovery of lossy compressed music based on CNN super-resolution and GAN. IEEE 3rd International Conference on Frontiers Technology of Information and Computer (ICFTIC), 623–629. doi:10.1109/ICFTIC54370.2021.9647041
Huang, Q., Liu, T., Wu, X., & Qu, T. (2019). A generative adversarial net-based bandwidth extension method for audio compression. Journal of the Audio Engineering Society, *67*(12), 986–993. doi:10.17743/jaes.2019.0047
Passricha, V., & Aggarwal, R. K. (2020). A hybrid of deep CNN and bidirectional LSTM for automatic speech recognition. Journal of Intelligent Systems, *29*(1), 1261–1274. doi:10.1515/jisys-2018-0372
Yoshimura, T., Hashimoto, K., Oura, K., Nankaku, Y., & Tokuda, K. (2018). WaveNet-based zero-delay lossless speech coding. IEEE Spoken Language Technology Workshop (SLT), 153–158. doi:10.1109/SLT.2018.8639598
Zeghidour, N., Luebs, A., Omran, A., Skoglund, J., & Tagliasacchi, M. (2022). SoundStream: An end-to-end neural audio codec. IEEE/ACM Transactions on Audio, Speech, and Language Processing, *30*, 495–507. doi:10.1109/TASLP.2021.3129994
Nogales, A., Donaher, S., & García-Tejedor, Á. (2023). A deep learning framework for audio restoration using convolutional/deconvolutional deep autoencoders. Expert Systems with Applications, *230*, 120586. doi:10.1016/j.eswa.2023.120586
Nagaraj, P., Rao, J. S., Muneeswaran, V., Kumar, A. S., & Sudar, K. M. (2020). Competent ultra data compression by enhanced features excerption using deep learning techniques. International Conference on Intelligent Computing and Control Systems (ICICCS), 1061–1066. doi:10.1109/ICICCS48265.2020.9121126
Q Chen, Q., Wu, W., & Luo, W. (2021). Lossless compression of sensor signals using an untrained multi-channel recurrent neural predictor. Applied Sciences, *11*(21), 10240. doi:10.3390/app112110240
Wang, J., Xie, X., & Kuang, J. (2014). A novel multichannel audio signal compression method based on tensor representation and decomposition. China Communications, *11*(3), 80–90. doi:10.1109/CC.2014.6825261
Shin, S., Byun, J., Park, Y., Sung, J., & Beack, S. (2022). Deep neural network (DNN) audio coder using a perceptually improved training method. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 871–875. doi:10.1109/ICASSP43922.2022.9747575